OpenFog Consortium Reference Architecture Executive Summary
OpenFog Consortium Reference Architecture Executive Summary
- Last Updated: December 2, 2024
Yitaek Hwang
- Last Updated: December 2, 2024

Last December, Matt Quirion wrote about the Big Three’s (Microsoft, Amazon, Google) push into fog computing. This week, fog computing reached another milestone as OpenFog Consortium — a group of big name players including Cisco, Intel, and ARM Holdings — released their executive summary of their massive 162 page reference architecture document. No one has time to read 162 pages of technical document, so we’ve summarized the most important points and why you should care here!
What is Fog Computing?
Fog computing was mentioned in Calum McClelland’s “Hey IoT, your head is in the Clouds,” but was only introduced as an alternative to cloud computing. Before we discuss why the two can be mutually beneficial, let’s define fog computing:
Fog computing is a horizontal, system-level architecture that distributes computing, storage, control and networking functions closer to the users along a cloud-to-thing continuum.
If that esoteric definition provided by the OpenFog Consortium doesn’t make sense to you, think of fog computing as an extension of the cloud to the edge — to end nodes and devices. It simplifies IoT applications because it removes consistent cloud connectivity and delivers low latency computations.

Consider an industrial application where you want to use pressure sensors, flow sensors, and control valves to monitor an oil pipeline. The traditional cloud computing model would send all the readings to the cloud, analyze them using machine learning algorithms to detect abnormalities, and send appropriate fixes down to the end devices.
But do we really need to send all the readings to the cloud? At scale, the bandwidth to simply push sensor readings becomes significant, not to mention the cost and the time to send and receive messages. In the time it takes to send an abnormal reading from a sensor, categorize as a potential leak in the cloud, and send a downlink message to notify personnel or stop the flow, the leak might have turned into a major spill.
Contrast that with a fog computing infrastructure: sensors will now send data to inexpensive local fog nodes where abnormality detection can happen locally and send commands to shut off the leaky valves within milliseconds, instead of minutes. This example illustrates how fog nodes can extend the role of the cloud down to a fog level for added benefit.
So No More Cloud?
While fog computing improves latency and network efficiency in certain Applications, this doesn’t mean that fog computing will replace the cloud. Rather, they’re mutually beneficial and can augment the ability of one another. Most of the decisions and data analytics traditionally computed on the cloud level can now move to the fog nodes to speed up response time. Still, the cloud can be useful in doing more historical data computation for predictive analytics or sending down commands or updates.
In essence, fog-cloud architecture combines the benefits for both designs: it provides low latency data transfer, while handing off other data for historical analytics. Given these characteristics, OpenFog Consortium summarizes its advantages over other approaches using SCALE (direct quote from the report):
- Security: additional layer of trusted data transfer
- Cognition: awareness of client-centric objectives to enable autonomy
- Agility: rapid innovation and affordable scaling under a common infrastructure
- Latency: real-time processing and cyber-physical system control
- Efficiency: dynamic pooling of local unused resources from participating end-user devices
Why should I care?
Having a standards body benefits both businesses and consumers. The reference architecture will help ensure interoperability of the different fog computing infrastructures. Consumers or developers can expect a more defined process to build systems that make IoT more accessible.
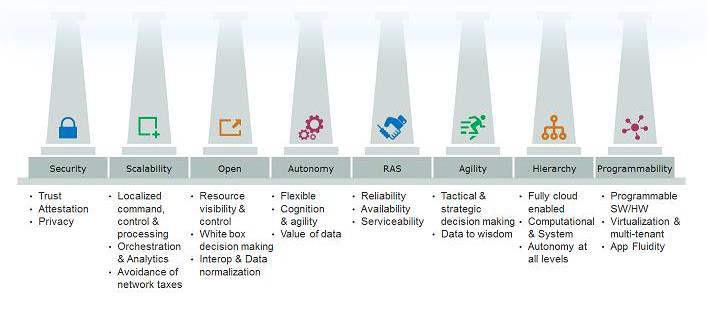
It’s clear that Azure IoT, AWS Greengrass, and Android Things all aim to move several IoT operations onto the fog level. IoT is already plagued with the fragmentation of various connectivity options. Hopefully, OpenFog Consortium will help ensure that these new fog computing moves will abide by these eight basic pillars:
The Most Comprehensive IoT Newsletter for Enterprises
Showcasing the highest-quality content, resources, news, and insights from the world of the Internet of Things. Subscribe to remain informed and up-to-date.
New Podcast Episode

What is Software-Defined Connectivity?
Related Articles


